Qu’est-ce que ETL ?
Si vous avez déjà travaillé avec des équipes spécialisées dans les données, vous avez probablement entendu l'acronyme ETL utilisé comme si tout le monde savait déjà ce qu'il signifie. Il signifie Extraction, Transformation, Chargement — trois mots apparemment simples qui décrivent l'un des processus les plus importants de la gestion moderne des données. Que vous construisiez un tableau de bord de ventes, que vous entraîniez un modèle d'apprentissage automatique, ou que vous essayiez simplement de faire communiquer deux systèmes, il est fort probable que l'ETL travaille discrètement en arrière-plan.
Cette page présente une introduction simple et accessible à ce qu'est l'ETL, à son fonctionnement et aux raisons pour lesquelles la quasi-totalité des organisations qui utilisent les données en dépendent.
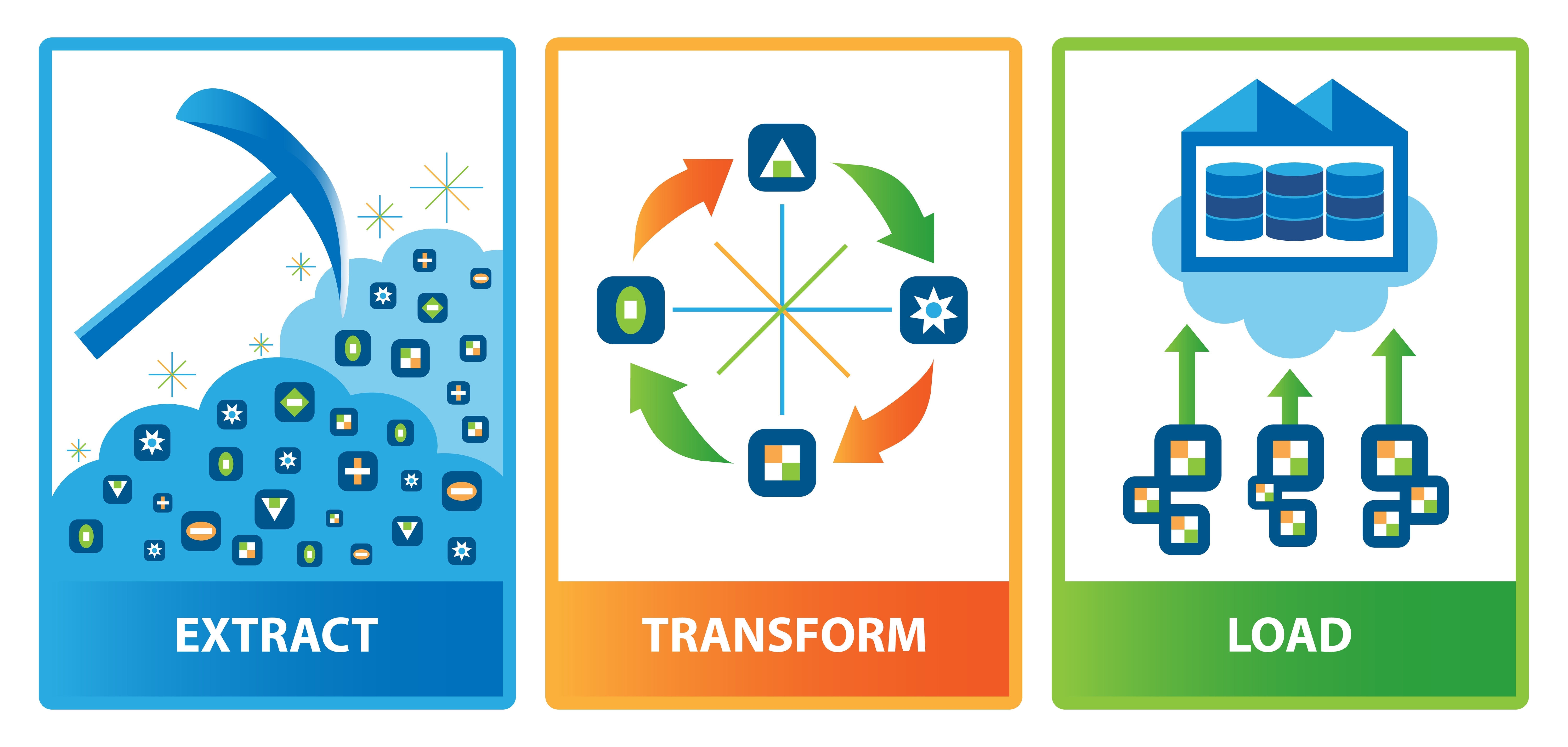
L'ETL, expliqué simplement
Au fond, l'ETL est un intégration de données Un processus qui extrait des données provenant d'une ou plusieurs sources, les reformate dans un format propre et cohérent, et les enregistre dans un emplacement où elles peuvent être effectivement utilisées IBM l'affirme, L'ETL (Extraction, Transformation, Chargement) "combine, nettoie et organise les données provenant de plusieurs sources afin de les regrouper dans un ensemble de données unique et cohérent."
Pour vraiment comprendre les bases, imaginez que vous cuisinez un repas. Vos ingrédients bruts proviennent de différents endroits : le jardin, la réserve, le marché. Avant de pouvoir servir un plat fini, vous les lavez, les coupez et les combinez selon une recette. L'ETL, c'est ce processus de préparation en cuisine, appliqué aux données. Les ingrédients bruts sont vos systèmes dispersés, la recette est votre ensemble de règles métier, et le plat fini est des données propres, prêtes à être analysées, stockées dans un entrepôt de données ou un autre référentiel.
Les trois étapes : Extraction, Transformation, Chargement
Chaque lettre représente une étape distincte du processus qui transforme les données brutes en informations exploitables.
Extrait
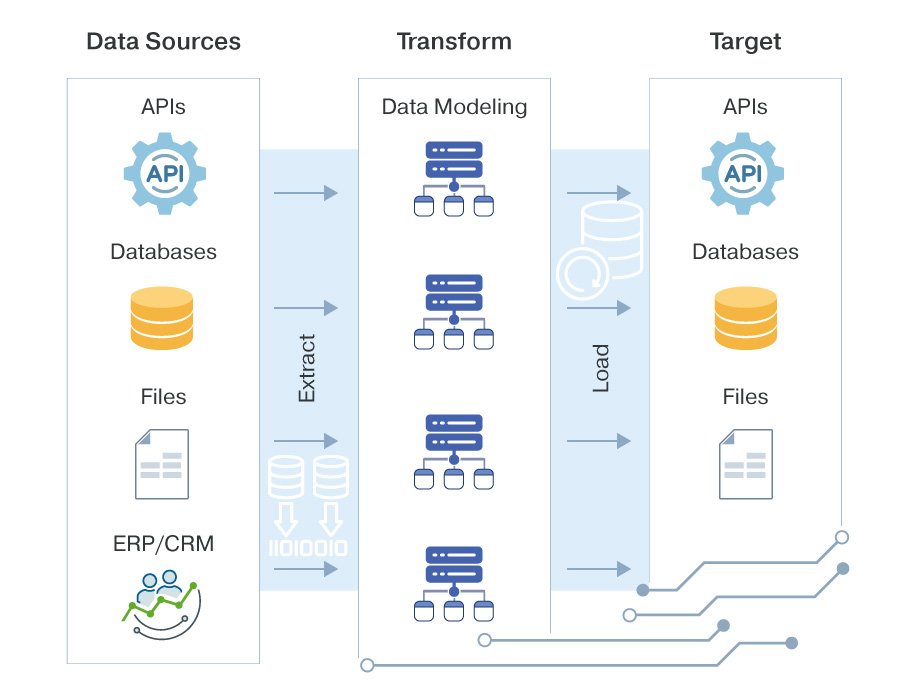
Dans le extrait Lors de cette étape, les données sont copiées ou extraites de leurs sources d'origine vers une zone de stockage temporaire, souvent appelée zone de préparation. Les sources sont variées : bases de données SQL et NoSQL, systèmes CRM et ERP, boutiques en ligne Shopify, feuilles de calcul, fichiers plats, API, pages web, et de plus en plus, des flux de données provenant de capteurs intégrés à des appareils connectés. Chacune de ces sources peut stocker des informations dans son propre format – XML, JSON, CSV, EDI, et bien d'autres – ce qui explique pourquoi l'étape suivante est si importante.
Transformer
L'étape de transformation est celle où le travail principal est effectué, et elle est généralement la partie la plus complexe du processus. Les données brutes sont nettoyées, validées et restructurées pour correspondre à la structure attendue par le système de destination. La transformation peut impliquer des opérations de base telles que la suppression des doublons et la modification des formats, ainsi que des opérations plus avancées comme la dérivation de nouvelles valeurs, la combinaison d'enregistrements provenant de différentes sources, la division de champs et la synthèse de grands volumes de données. C'est cette étape qui transforme des données incohérentes et désordonnées en informations fiables. Les devises sont normalisées, les clients en double sont fusionnés, les valeurs manquantes sont traitées, et les champs sensibles peuvent être masqués ou cryptés afin de répondre aux exigences réglementaires.
Charge
Enfin, lors de l'étape de chargement, les données transformées sont écrites dans le système cible, qui est généralement un entrepôt de données, un lac de données, une base de données ou un outil d'analyse. Le chargement peut se faire de manière unique, avec un chargement complet de toutes les données historiques, ou de manière continue, avec des chargements incrémentaux qui ajoutent uniquement les données modifiées depuis la dernière exécution. La plupart des organisations automatisent cette étape afin que les données soient mises à jour en continu, souvent pendant les heures creuses, lorsque les systèmes sont moins sollicités.
Pourquoi l'ETL est-il important ?
Sans ETL, les données restent isolées, formatées de manière incompatible et truffées d'erreurs et de doublons. Les analystes passent alors plus de temps à manipuler des feuilles de calcul qu'à réellement analyser des données. L'ETL résout ce problème en automatisant les tâches répétitives et en fournissant une vue unique, consolidée et fiable de l'entreprise. Cette base permet de mener à bien un large éventail d'activités :
- L'intelligence d'affaires et la production de rapports, où des données propres alimentent des tableaux de bord et des rapports.
- L'intégration et l'unification de systèmes d'entreprise disparates, en particulier dans le cadre de fusions et acquisitions.
- L'entrepôt de données, qui repose sur les processus ETL (extraction, transformation, chargement) pour consolider les données historiques et les données actuelles.
- L'apprentissage automatique et l'analyse avancée, qui nécessitent des données d'entraînement soigneusement préparées.
- Conformité réglementaire, où les données doivent être traitées et stockées conformément à des règles strictes.
- Efficacité opérationnelle, grâce à l'élimination de la saisie manuelle des données et des erreurs qui y sont associées.
Un bref historique
L'ETL n'est pas une technologie récente. Elle a émergé dans les années 1970, parallèlement au développement des bases de données centralisées, et est devenue la méthode standard pour alimenter les entrepôts de données une fois que les bases de données relationnelles ont gagné en popularité à la fin des années 1980. Les premières tentatives étaient largement réalisées par des équipes informatiques grâce à du code écrit manuellement. Avec l'explosion des volumes de données à l'ère du "big data", puis avec le passage vers le cloud, les outils ETL sont devenus beaucoup plus sophistiqués, intégrant des interfaces graphiques, l'automatisation, le traitement en temps réel et des fonctionnalités de cartographie assistées par l'intelligence artificielle.
Quels sont les critères à prendre en compte lors du choix d'un outil ETL
Les logiciels ETL modernes simplifient considérablement le processus, vous évitant ainsi d'avoir à écrire du code d'intégration manuellement. Lors de l'évaluation des différentes options, les qualités les plus importantes sont une connectivité étendue aux formats de données et aux systèmes que vous utilisez réellement, une interface conviviale (souvent avec peu de code ou par glisser-déposer), une capacité d'intelligence artificielle intégrée qui peut automatiquement associer les sources aux cibles en fonction de leur signification, la capacité de gérer des transformations complexes, une automatisation et une planification robustes, une sécurité et une conformité solides, et un prix qui reste prévisible à mesure que vos besoins évoluent. La meilleure façon d'évaluer un outil est de l'essayer dans un contexte réel, alors recherchez-en un qui propose une période d'essai gratuite et entièrement fonctionnelle.
L'acronyme ETL peut sembler technique, mais l'idée qui le sous-tend est étonnamment simple : extraire vos données de leur emplacement actuel, les nettoyer et les placer dans un endroit où elles pourront être utilisées. Si vous faites cela correctement, de manière constante et automatisée, le reste de votre stratégie de données bénéficiera de bases solides.